Making AI understand your users' research
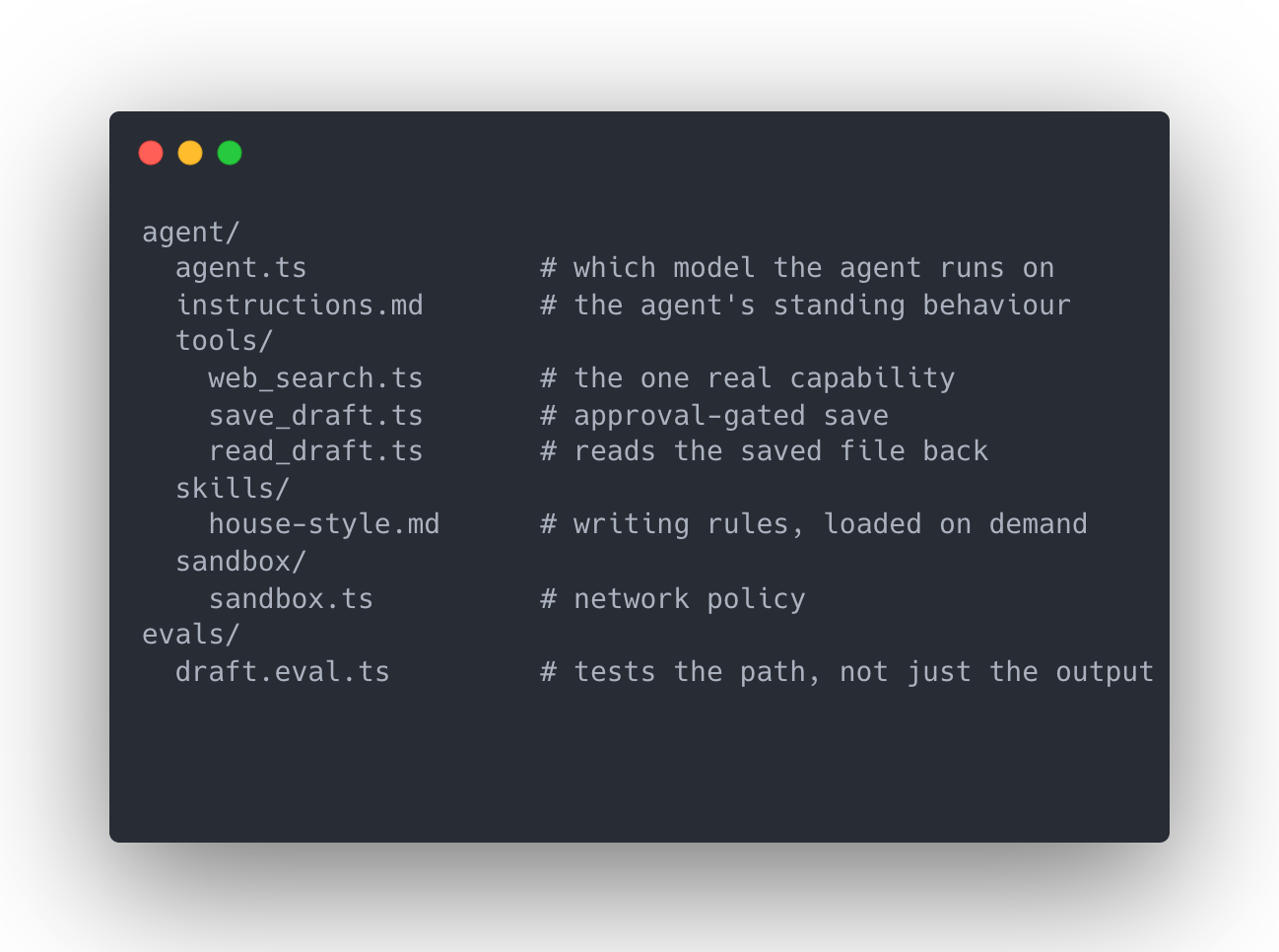
Notes from a handful of RAG builds this year, some client features and some internal tooling, all circling the same questions about chunking, retrieval, and architectural restraint. The specifics below draw from a recent build: a Knowledge Bases feature in a multi-model AI editor, shipped in about a week.

Every SaaS product has an AI feature now. A chat sidebar. A "generate" button. An assistant that answers whatever you type and forgets everything the moment you close the tab.
We've been working on the harder version of that across several projects this year, some for clients and some internal to the studio. All of them needed an AI that could actually read user-provided material before helping with it. Not a chatbot, but an assistant with context. One that knows what you know.
The pattern is usually a variant of a Knowledge Base: users upload sources (PDFs, articles, videos, notes), add reference examples, sometimes write custom instructions. The AI draws on all of it during conversations. Like briefing a new colleague: hand them the background reading, show them what good looks like, explain the brief. Then they can actually help.
The specifics below come from a recent build: a Knowledge Bases feature in a multi-model AI editor. Most of the decisions generalise. Here's how we thought about it.
Three ways to feed an AI your content
We mapped the options before writing any code. This decision sits underneath everything else, get it wrong and you're rebuilding later.
1. Context stuffing. Paste every source directly into the AI's input. No indexing, no retrieval step. The AI sees everything.
This works well when there isn't much material. But AI models have limits on how much text they can process at once, and those limits vary. Some models handle 128K, others 200K, others north of 1M and the ceilings keep moving. A Knowledge Base that runs perfectly on one model can silently fail on another. Cost scales linearly too, every message sends every source, even when 90% of it has nothing to do with the question.
2. RAG (Retrieval-Augmented Generation). Split each source into smaller sections, generate mathematical representations of their meaning (embeddings), and store them in a vector database. When the user asks a question, embed the question, find the most similar sections, and send only those to the AI.
Scales to any size. Works the same across models. One code path. Slightly less effective on very small Knowledge Bases, where the AI would benefit from seeing everything in full.
3. Hybrid. Switch between the two based on size. In theory, the best of both approaches. In practice, two code paths and double the testing surface. Every bug potentially exists in two variants, and the threshold between "small" and "large" shifts with every model.
We went with RAG. One pipeline for every scale, every model, no conditional logic. And if small-KB quality ever becomes a problem, adding the simpler approach on top is straightforward. Going the other way (bolting retrieval onto a system that assumed everything fits) is a rewrite.
Choosing the tools
We used Mastra, an open-source TypeScript AI framework, to handle the RAG pipeline. It gave us chunking strategies, embedding orchestration, vector storage via pgvector (which runs directly inside PostgreSQL, so no separate database to manage), and retrieval tools that wire straight into the AI agent.
Why Mastra over building it ourselves? The individual pieces (splitting text, calling an embedding API, querying vectors) aren't complex on their own. The orchestration between them is where bugs hide. A maintained framework handles the glue and lets us focus on the product.
Why pgvector over a dedicated vector database like Pinecone or Weaviate? The stack already ran on Supabase (hosted PostgreSQL). Adding pgvector meant the vector store lives in the same database as everything else: same backups, same access control, same infrastructure. One fewer service to look after.
Mastra launched in late 2024, so we thought carefully about depending on a young framework. The RAG primitives are thin and open-source. If the project was abandoned tomorrow, the logic is straightforward to reimplement, and the data model and vector store stay the same.
Chunking: where retrieval quality lives or dies
If there's one decision in the RAG pipeline that matters more than any other, it's how you split documents into chunks. One framing we found useful puts it bluntly: "80% of RAG failures trace back to the ingestion and chunking layer, not the LLM." That lines up with our experience across builds, when retrieval feels off, the chunker is almost always the first place to look.
Before we settled on an approach, we looked at the options properly. Firecrawl has a good survey of the landscape that saved us a lot of reading. A quick tour of what we considered:
Fixed-size chunking. Count characters or tokens, split at the limit. Three lines of code. Fragments sentences mid-thought and ignores document structure. Ruled out early.
Sentence-based chunking. Detect sentence boundaries, group sentences until you hit a target size. Better for short-form Q&A content. Users in these products upload long, structured PDFs, which would have produced wildly variable chunks.
Semantic chunking. Use embeddings to detect topic shifts and split at those boundaries. Can improve recall by around 9% in some studies, but it costs an embedding call per sentence during ingestion. For a feature where users upload a lot of material, this turns into real money quickly. Filed as "worth revisiting if retrieval quality becomes the blocker."
Hierarchical chunking. Store small chunks for precise retrieval alongside large parent chunks for full context. Genuinely compelling. We considered it seriously and may come back to it. Probably where we'd go if retrieval quality on small Knowledge Bases turns out to be weak.
Summary-based approaches. Pre-summarise each chunk (or each document) and use the summaries for retrieval, surfacing the raw chunks only during generation. Useful when source content is dense and repetitive. Added complexity we didn't need for a first version.
Late chunking. Embed the full document first, then split, so every chunk's vector carries document-wide context. Strong for pronoun-heavy and cross-referential content (legal contracts, academic papers). Requires the whole document to fit in the embedder's context window, which made it impractical for our source profile.
Recursive chunking. Split on paragraph boundaries, then sentences, then characters, using a hierarchy of separators. Preserves natural document structure. Fast. What we picked.
Our numbers versus the guidance
Most public guidance, including the Firecrawl piece above, recommends 400 to 512 token chunks with 10 to 20% overlap as the sensible default. We went larger: 1,000 tokens with a 200-token overlap (still 20%, but double the chunk size).
The reasoning: for long-form research material, smaller chunks fragmented ideas that legitimately spanned multiple paragraphs. A single paragraph rarely tells the full story on its own, and retrieving just one often dropped the reader into the middle of an argument. We'd rather pass more context to the model and let it filter, than pass less and lose the thread.
This is a judgment call, not a fact. If your content is short-form (support articles, product descriptions, chat logs), 400 to 512 is probably right. If it's long-form and dense (research papers, briefs, essays), larger chunks tend to preserve more of what matters. Start larger than you think you need and adjust down if retrieval starts missing obvious hits.
Why keep the overlap
Ideas that span chunk boundaries shouldn't vanish into the gap. Overlap keeps things continuous. There's a recent argument (noted in the Premai RAG write-up) that overlap provides no measurable benefit with SPLADE-style retrieval, and only adds storage cost. That's worth knowing. It's not our retrieval stack, so overlap still earns its place for us.
Design decisions that mattered
Not everything should be chunked
Sources (PDFs, articles, transcripts) go through the full RAG pipeline. They can be large, and users may have dozens. Retrieving the relevant sections works well here.
But "examples" (reference documents that show the kind of output the user wants) need to be read in full. The AI has to see the whole thing to pick up on structure, tone, and style. Chunking a style reference into fragments defeats the purpose. So we treated them differently: RAG for sources, full inclusion for examples.
Isolation at the infrastructure layer
When multiple users store material in the same vector database, you need guarantees that one user's queries can't surface another user's content.
The naive approach is to tell the AI "only use sources from this user's Knowledge Base." That's a suggestion in a prompt. It can leak.
So we built a scoping layer that forces a Knowledge Base filter onto every vector query. The system physically cannot return results from a Knowledge Base the user doesn't have access to. Combined with authentication checks before the AI agent even starts, this gives us defence in depth without relying on prompt-level instructions for security.
Source citations
When the agent retrieves material to answer a question, we surface which sources it drew from. Badges appear below each response with titles and source types: "Based on: Research Paper · Company Blog · Product Demo."
A small thing to build, but it changed how users related to the feature. They didn't just want good answers, they wanted to see the working. Citations turn the AI from a black box into something people are willing to trust with real work.
Two-step ingestion
Processing a large PDF (extracting text, chunking it, generating embeddings, storing vectors) takes time. The user shouldn't sit watching a spinner on the upload button.
So we separated upload from processing. The source appears in the interface straight away. Processing runs in the background with a clear status indicator, and if it fails, the user can retry without re-uploading. This pattern also keeps server-side processing within the timeout limits of serverless platforms.
What we learned
A few things we'd carry into the next project.
Build the retrieval pipeline first. "We'll just include everything and add RAG later" sounds pragmatic, but retrieval is the hard part. The simpler path is easy to layer on top of it.
Show your sources. Citations aren't a nice-to-have. They're what makes people trust an AI feature with work that matters to them.
When picking a framework, think about replaceability, not just features. We chose Mastra knowing it was young. The deciding factor wasn't maturity, it was that the primitives are thin enough to rewrite if we ever had to. The data lives in PostgreSQL either way.
Don't over-engineer the first version, but document every shortcut. Every trade-off came with a clear upgrade path on paper. That discipline is part of why we could move quickly on this, getting it into production in about a week, without the technical debt showing up later as a quiet tax.
Different content types need different strategies. The instinct is to put everything through the same pipeline. Resist it. Source material and style examples serve different purposes, and treating them the same compromises both.
Let's talk
Most of what's above are judgment calls more than right answers. Thinking through problems like these — and building the thing on the other side of them — is what we enjoy most. If you're working through something similar, we'd be glad to help you figure it out, build it alongside you, or just take the whole thing off your plate. Whichever makes sense.
HAM Studio is a software engineering studio based in London and Brentwood. We're problem-solvers at heart, helping startups and growing businesses build, launch, and scale digital products. See our work →
Related Post

Let's build something together
Feel free to contact us

©2026 H.A.M. Digital Ltd trading as HAM Studio®.
Registered in England & Wales No. 08355825.
Registered office: 9 Corbets Tey Road, Upminster, England, RM14 2AP